Lecture 1: Introduction to Visualization and Basic Plots
Objective: - Introduce basic bioinformatics visualization techniques using R Histogram, Scatter Plot, Box Plot, Line Plot
- Overview of syntax using simulated data - Explore basic plots using nhanes data. - Exercise 1
Load necessary libraries
library(ggplot2)library(dplyr)
Warning: package 'dplyr' was built under R version 4.3.2
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(readr)
Warning: package 'readr' was built under R version 4.3.2
library(tidyr)
Warning: package 'tidyr' was built under R version 4.3.2
Generate synthetic data
# set.seed ensures that the sequence of random numbers generated can be reproduced.set.seed(123)data <-data.frame(Time =1:50,# rnorm() = random normal is used to generate random numbers from a normal distribution."X =rnorm(50, mean =5, sd =2),Y =2*rnorm(50, mean =5, sd =2) +rnorm(50),# c("A", "B") creates a vector containing the elements "A" and "B"# each = 25 specifies that each element in the vector should be repeated 25 timesGroup =rep(c("A", "B"), each =25))
Histogram Plot: Histograms are useful to show the distribution of a single continuous variable
# Create the histogram using ggplot2histogram_plot <-ggplot(data, aes(x = X)) +geom_histogram(binwidth = (max(data$X) -min(data$X)) /10, fill ="purple", color ="white") +ggtitle("Histogram") +xlab("Value") +theme_minimal() +theme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") )# Display the plothistogram_plot
# Save the plot to a fileggsave("3_histogram_plot.png", plot = histogram_plot, width =8, height =6, dpi =300)
Scatter Plot: Scatter plots are useful to show the relationship between two continuous variables
# Create the scatter plot with a white backgroundScatter_plot <-ggplot(data, aes(x = X, y = Y)) +geom_point() +ggtitle("Scatter Plot") +xlab("X-axis") +ylab("Y-axis") # Display the plotScatter_plot
# Save the plot to a fileggsave("1_scatter_plot.png", plot = Scatter_plot, width =8, height =6, dpi =300)
Box Plot: Box plots are useful to show the distribution of a continuous variable
# Box Plot# Create the box plotBox_plot <-ggplot(data, aes(x = Group, y = Y, fill = Group)) +geom_boxplot() +ggtitle("Box Plot") +xlab("Group") +ylab("Value") +scale_fill_manual(values =c("red", "green")) +theme_minimal() +theme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") )# Display the plotBox_plot
# Save the plot to a fileggsave("2_box_plot.png", plot = Box_plot, width =8, height =6, dpi =300)
Line Plot: Line plots are useful to show trends over time or another continuous variable
# Create the line plot using ggplot2data$Value <-cumsum(rnorm(50))line_plot <-ggplot(data, aes(x = Time, y = Value)) +geom_line(color ="orange", linewidth =1.5) +# Set line color and thicknessggtitle("Line Plot") +xlab("Time") +ylab("Value") +theme_minimal() +theme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") )# Display the plotprint(line_plot)
# Save the plot to a fileggsave("4_line_plot.png", plot = line_plot, width =8, height =6, dpi =300)
Load a healthcare dataset: nhanes (National Health and Nutrition Examination Survey)
# Actual Dataset Read the data from the provided URLNHANES <-read_csv("https://raw.githubusercontent.com/GTPB/PSLS20/master/data/NHANES.csv", show_col_types =FALSE)# Extract only the columns ID, Age, BMI, and BloodPressurenhanes_subset <- NHANES %>%select(ID, Age, BMI, BloodPressure = BPSysAve) %>%distinct(ID, .keep_all =TRUE) %>%drop_na()# Display the first few rows of the subsetprint(head(nhanes_subset))
# Write the cleaned dataset to a CSV filewrite_csv(nhanes_subset, "health_data.csv")# Display summary of the cleaned datasetprint(summary(nhanes_subset))
ID Age BMI BloodPressure
Min. :51624 Min. : 8.0 Min. :12.89 Min. : 76
1st Qu.:56548 1st Qu.:22.0 1st Qu.:22.65 1st Qu.:106
Median :61574 Median :39.0 Median :26.63 Median :116
Mean :61623 Mean :40.3 Mean :27.58 Mean :118
3rd Qu.:66765 3rd Qu.:56.0 3rd Qu.:31.30 3rd Qu.:127
Max. :71915 Max. :80.0 Max. :81.25 Max. :226
Visualization
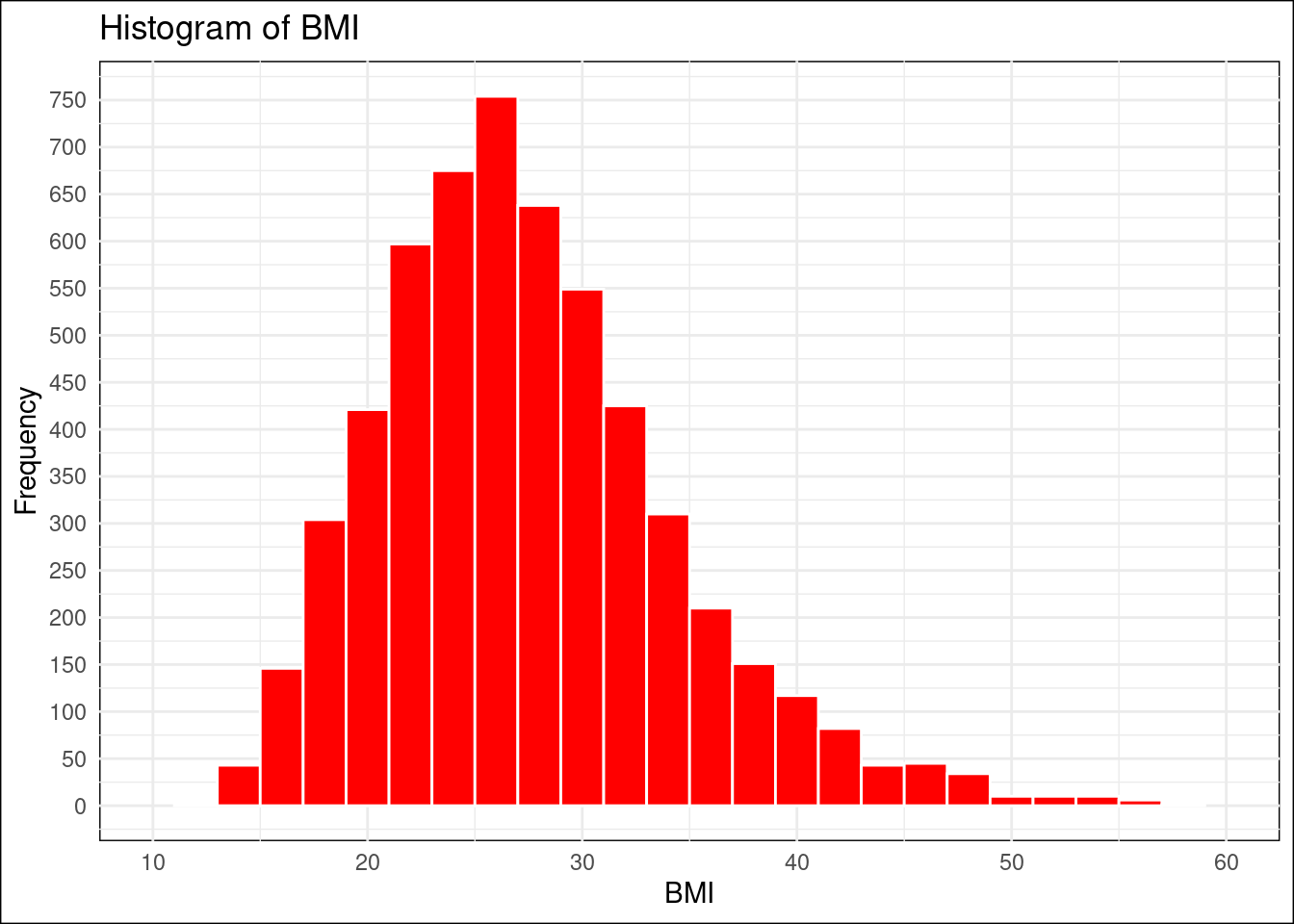
Histogram
# Filter out non-finite values from the BMI columnnhanes_subset <- nhanes_subset %>%filter(is.finite(BMI))# Create a histogram of BMI with more ticks on the axesggplot(nhanes_subset, aes(x = BMI)) +geom_histogram(binwidth =2, fill ="red", color ="white") +ggtitle("Histogram of BMI") +xlab("BMI") +ylab("Frequency") +theme_minimal() +# Apply a minimal theme for a clean looktheme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") ) +xlim(0, 60) +# Trim the x-axis to show values between 10 and 60ylim(0, 800) +# Trim the y-axis to show values between 0 and 800scale_x_continuous(breaks =seq(0, 60, by =10), limits =c(10, 60)) +# More ticks on the x-axisscale_y_continuous(breaks =seq(0, 800, by =50)) # More ticks on the y-axis
Scale for x is already present.
Adding another scale for x, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Warning: Removed 12 rows containing non-finite outside the scale range
(`stat_bin()`).
Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_bar()`).
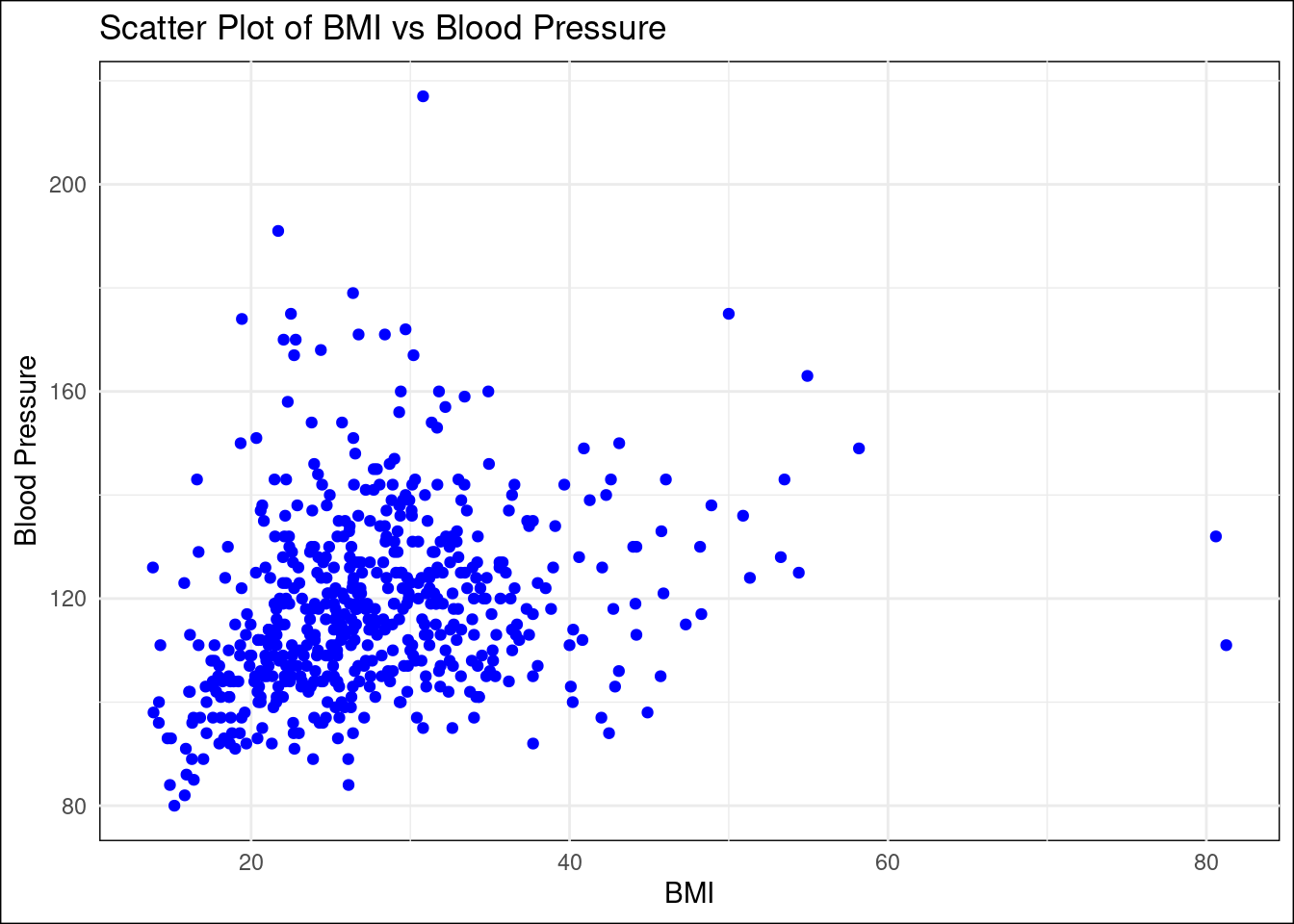
Scatter Plot:
# Create a scatter plot of BMI vs BloodPressure# Sample 10% of the data pointsnhanes_sampled_data <- nhanes_subset %>%sample_frac(0.1)# Create a scatter plot of BMI vs BloodPressure with the sampled dataggplot(nhanes_sampled_data, aes(x = BMI, y = BloodPressure)) +geom_point(shape =19, color ="blue") +ggtitle("Scatter Plot of BMI vs Blood Pressure") +xlab("BMI") +ylab("Blood Pressure") +theme_minimal() +# Apply a minimal theme with a white backgroundtheme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") )
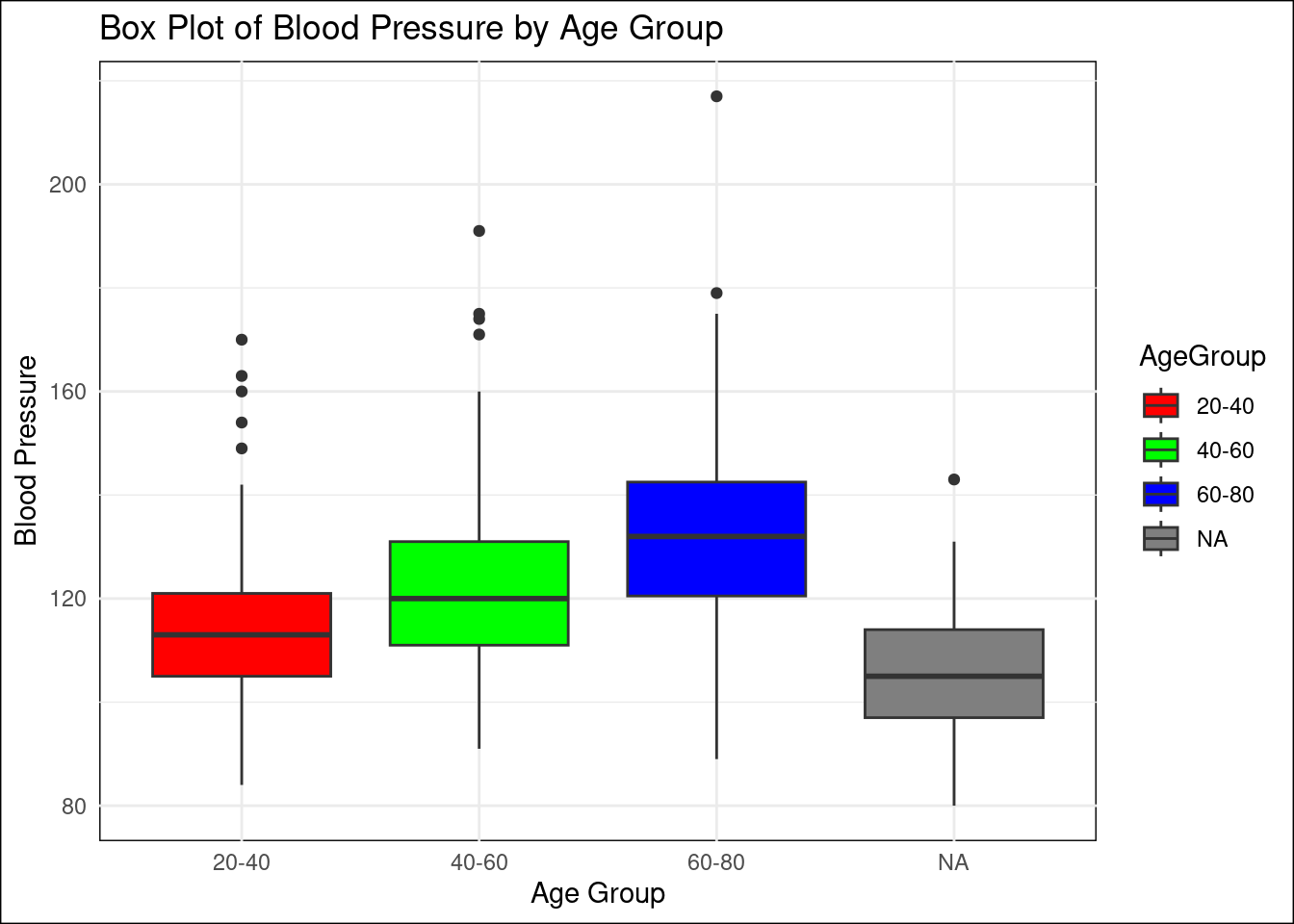
Box Plot:
# Create a box plot of BloodPressure by Age groups:nhanes_sampled_data <- nhanes_sampled_data %>%mutate(AgeGroup =cut(Age, breaks =c(20, 40, 60, 80), labels =c("20-40", "40-60", "60-80")))# Create a box plot of BloodPressure by Age groups with colorsggplot(nhanes_sampled_data, aes(x = AgeGroup, y = BloodPressure, fill = AgeGroup)) +geom_boxplot() +ggtitle("Box Plot of Blood Pressure by Age Group") +xlab("Age Group") +ylab("Blood Pressure") +scale_fill_manual(values =c("20-40"="red", "40-60"="green", "60-80"="blue")) +theme_minimal() +theme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") )
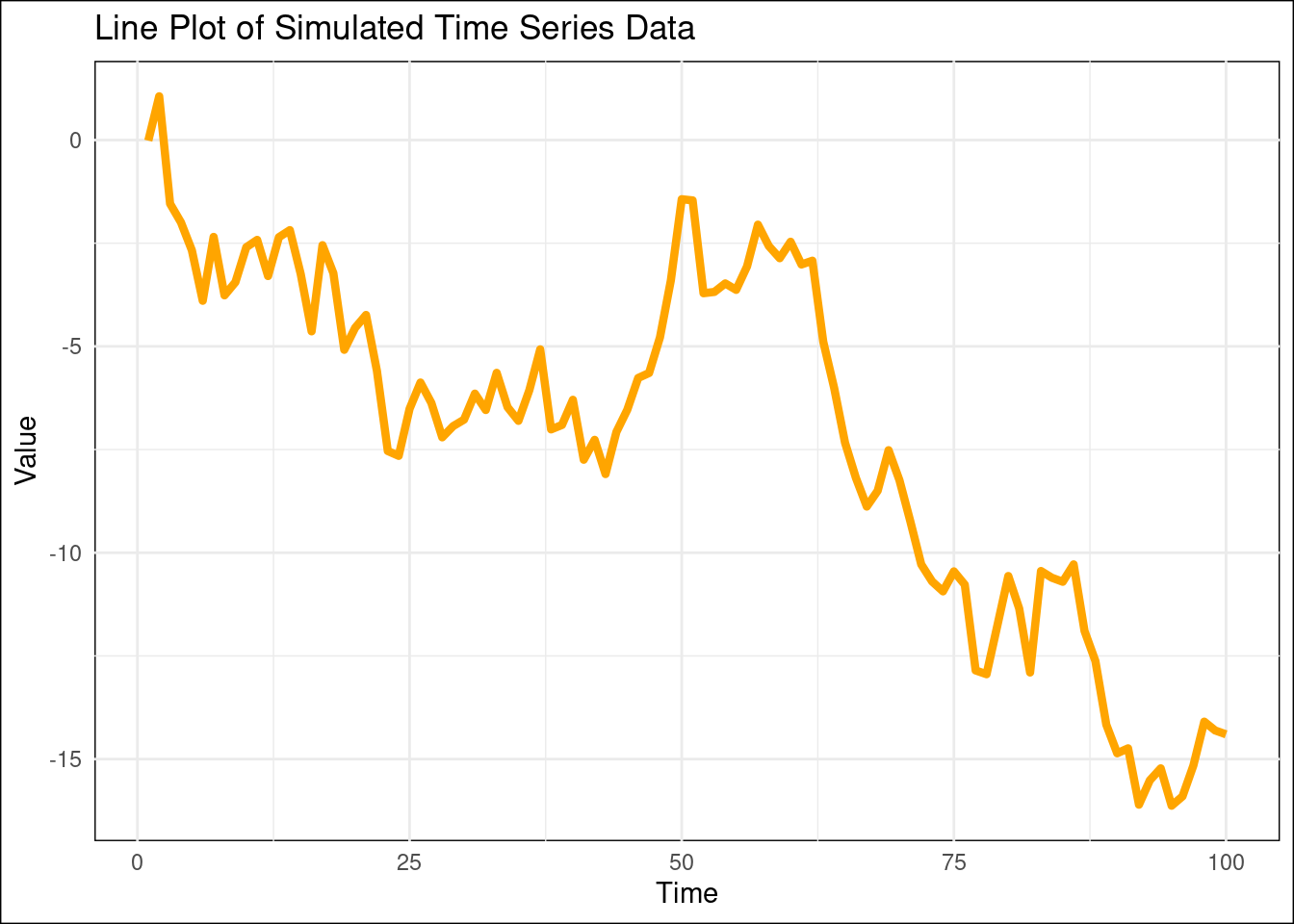
Line Plot:
# For this example, we'll simulate some time series datatime_series_data <-data.frame(Time =1:100,Value =cumsum(rnorm(100)))# Create a line plot of the time series dataggplot(time_series_data, aes(x = Time, y = Value)) +geom_line(color ="orange", linewidth =1.5) +ggtitle("Line Plot of Simulated Time Series Data") +xlab("Time") +ylab("Value") +theme_minimal() +theme(plot.background =element_rect(fill ="white"),panel.background =element_rect(fill ="white") )
—————————————Assignment 1: Part 1——————————————————–
Dr. Kate is investigating an illness affecting a group of individuals. She needs your help to visualize the nhanes data and uncover hidden patterns.
Scatter Plot Investigation: Dr. Kate suspects that age might influence BMI in her patients. Create a scatter plot using the nhanes dataset to visualize the relationship between Age and BMI. Identify any patterns or trends that might suggest an age-related trend in BMI.
# Solution a# Hint: Look for clusters or patterns suggesting that certain age groups are more prone to higher or lower BMI, indicating lifestyle or metabolic factors.
Box Plot Analysis: Dr. Kate wants to determine if certain age groups are at higher risk for elevated blood pressure. Generate a box plot for BloodPressure by AgeGroup in the nhanes dataset. Identify any age groups with higher or more variable blood pressure, indicating a health risk.
# Solution b# Hint: Notice any age group with outliers or higher blood pressure, suggesting that this group is at higher risk of the mysterious illness.
Histogram Examination: Dr. Kate is also interested in the distribution of BMI among her patients. Create a histogram of BMI. Analyze the distribution of BMI levels and identify common ranges and any outliers.
# Solution c# Hint: Identify common BMI ranges and any outliers. Individuals with significantly high or low BMI might be suffering from the mysterious illness, possibly linked to trends observed in blood pressure and age group